
.png)


Hadoop -MapReduce入门
使用mapreduce进行文字统计
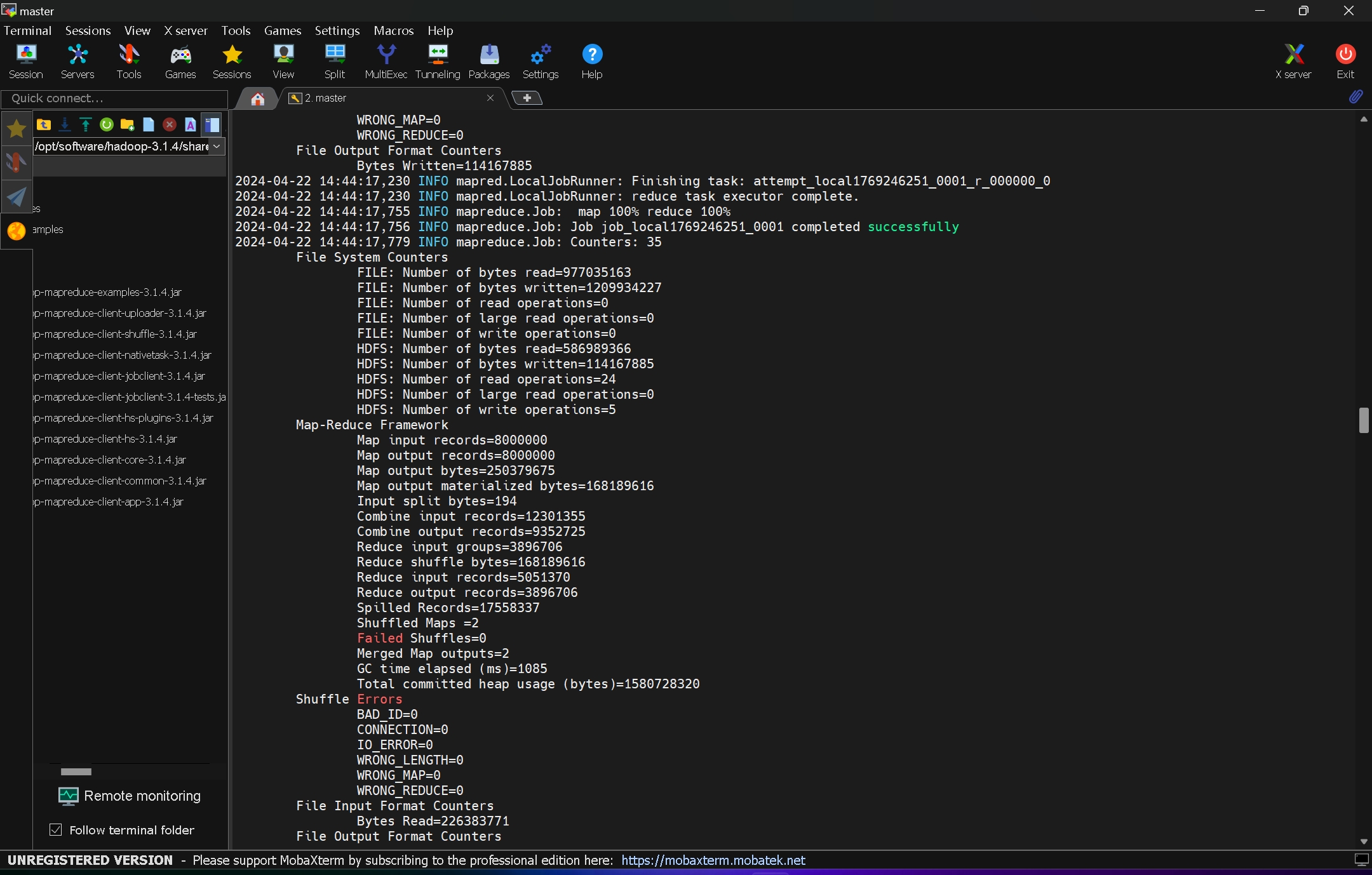 还可以使用内置的pi进行圆周率估算
还可以使用内置的pi进行圆周率估算
例如:
hadoop jar hadoop-mapreduce-examples-3.1.4.jar pi 10 100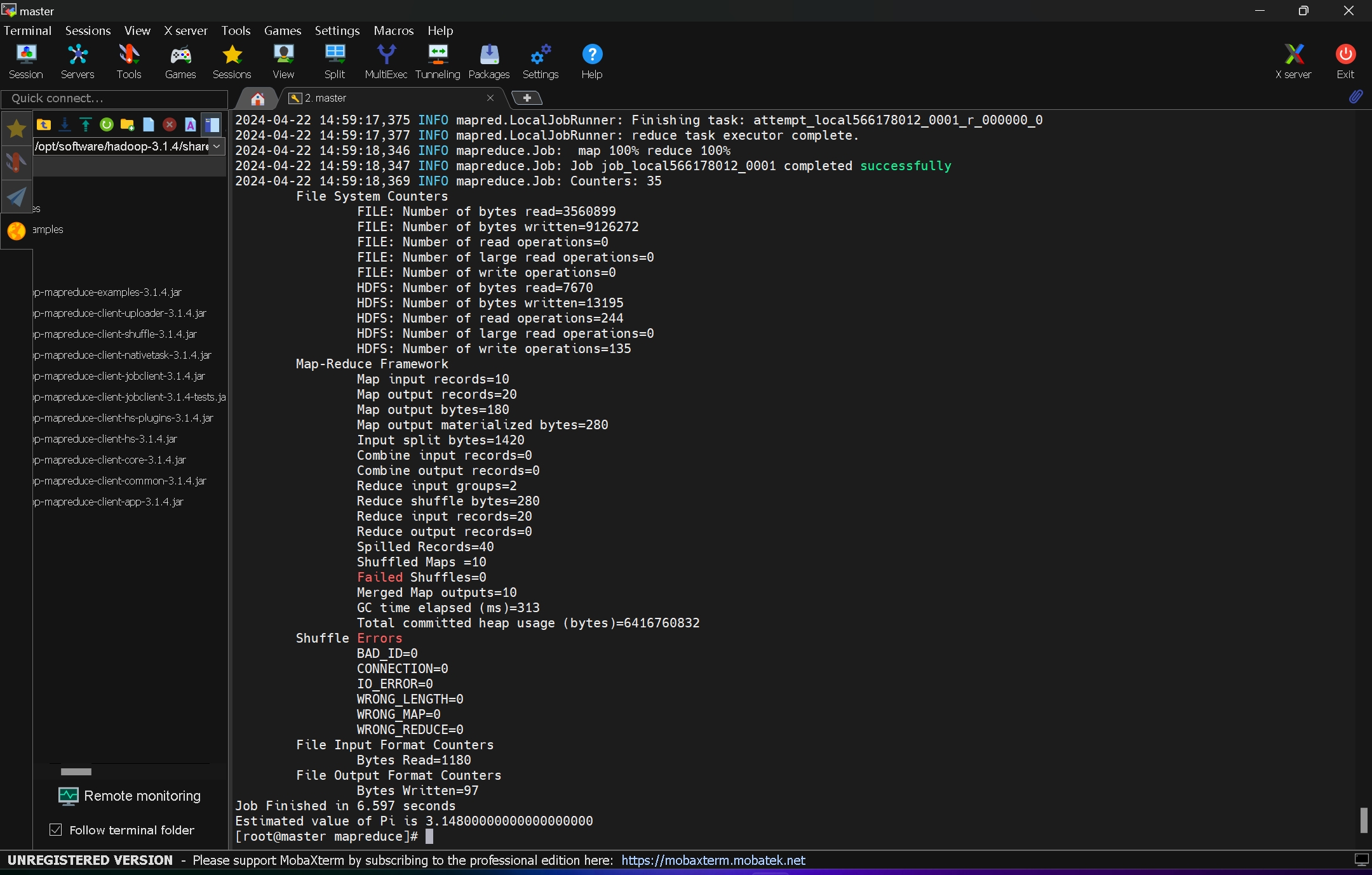 编写Map Reduce需要用到Idea,先配置Idea和java环境
编写Map Reduce需要用到Idea,先配置Idea和java环境
详见破解Idea并且创建简单的maven项目-聆尘风 (itqh.com.cn)
自定义配置连接hadoop集群java类
 新建一个普通的项目,Build system为Maven
新建一个普通的项目,Build system为Maven
创建成功后,将需要的依赖性(pom.xml)复制粘贴到pom.xml文件中
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>CQNY.Hadoop</groupId>
<artifactId>HadoopTest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.1.4</hadoop.version>
</properties>
<dependencies>
<!--hdfs-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<!-- 单元测试依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>compile</scope>
</dependency>
<!--webmagic-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.1</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.1</version>
</dependency>
<!--日志-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
</project>然后开始构建编译项目
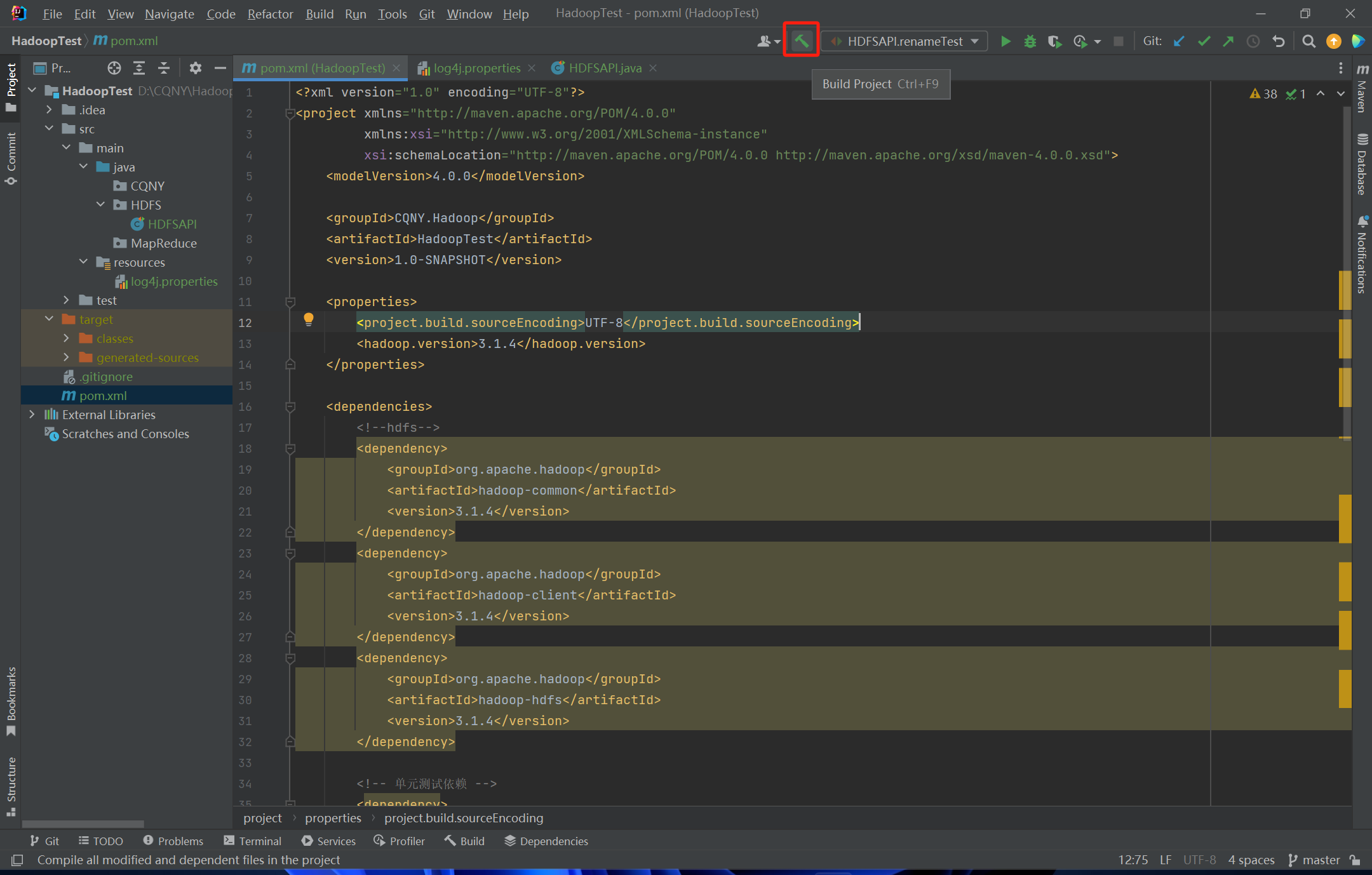 成功会显示successfully
成功会显示successfully
然后在java目录下新建HDFS文件夹,MapReduce文件夹,新建HDFSAPI.java文件,在resources下新建一个log4j.properties文件
 将准备好的配置文件粘贴进来
将准备好的配置文件粘贴进来
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n然后在HDFSAPI,java中输入以下内容:
package HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class HDFSAPI {
private FileSystem fs;//全局变量
/*
*文件系统对象的获取
*创建配置文件对象,加载配置文件中的信息
* 默认读取 core-default.xml hdfs-default.xml mapred-defaule.xml yarn-default.xml
* 如果项目中有配置文件 core-site.cml hdfs-site.xml mapred-site.xml yarn-site.xml
* 用户也可以在代码中编辑配置信息
* 属性的优先级:代码中的设置>*.site.xml >*-default.xml
*/
@Test
@Before
public void getFileSystemTest() throws IOException {
System.setProperty("HADOOP_USER_NAME","root");
//配置文件
Configuration conf = new Configuration();
//读取hadoop
conf.set("fs.defaultFS","hdfs://192.168.200.5:8020");//hdfs://填写master的ip地址,端口号也要配置正确
fs = FileSystem.get(conf);
System.out.println(fs.getClass().getName());
}
//HDFS继续您高座
//上传文件 从本地windows上传到HDFS中
@After
public void closeFileSystemTest() throws IOException{//抛出异常
fs.close();
}
@Test
public void uploadTest() throws IOException {//抛出异常
Path src = new Path("C:/Users/Chenfeng Ling/Desktop/abc.txt");//src代表文件上传的文件路径
Path dst = new Path("/");//上传的集群文件路径
fs.copyFromLocalFile(src,dst);//copyFromLocalFile是系统自带的函数
}
@Test
public void createDirTest() throws IOException{
// fs.mkdirs(new Path("/sqh"));
// fs.mkdirs(new Path("/sqh"));
Path dir = new Path("/kkk");
fs.mkdirs(dir);
}
@Test
public void downloadTest() throws IOException {
// fs.copyToLocalFile(true,new Path("/a.txt"),new Path("D:/CQNY/Hadoop/Down"),true);
fs.copyToLocalFile(true,new Path("/a.txt"),new Path("D:/CQNY/Hadoop/Down"),true);
}
@Test
public void deleteDirTest() throws IOException {
fs.delete(new Path("/abc.txt"),true);//文件和路径都能删除
//抛出异常:alt+enter
}
@Test
public void renameTest() throws IOException {
fs.rename(new Path("/a.txt"),new Path("/b.txt"));
}
}
需要注意的是,在整个文件中,导入的包都为hadoop,有个别类需要进行异常处理,抛出异常。
在文章中,Map Reduce又被称为MR
Map Reduce工作原理以及核心组成
Mapper Mapper助理InputFormat 输入文件读取器
Shuffle Shuffle助理Sorter 排序器
Reduce Reduce助理OutputFormat 输出结果写入器
在MR实现词频统计的时候先进行读取单词,输出中统计单词出现数据
数据分片:
Map Reduce通过数据分片的方式且前数据,将数据分发给多个单元进行处理,这也是分布式计算的第一步。
Map阶段处理:Map是一种数据格式,每个键都有对应的值,输入文件的每一行记录经过映射处理后输出为果敢组键值对。Map阶段生成键值对后,提交中间输出结果进入Reduce阶段。
读取过程--> <偏移量(起始位置),内容>
在java文件夹下新建一个WordCount包
新建三个java文件
WordCountDriver
WordCountMapper
WordCountReducer
一下为WordCountMapper类详细代码:
package WordCount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
*
* KEYIN: mapper 阶段输入的KEY的数据类型,本案例中,数据是一行一行的输入的,所以KEYIN的数据类型是整型,LongWritable(长整型),IntWritable(整形)
* VALUEIN: mapper阶段的输入的VALUE的数据类型,在本案例中对应的十一行数据,文本。为Text类型
* KEYOUT: mapper阶段的输出的KEY的数据类型这个阶段输出的是<单词,1>,所以为Text类型
* VALUEOUT: mapper阶段的输出的VALUE的数据类型,就是一个1,所以未IntWritable类型
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { //继承mapper
//定义本阶段要输出的k和v
Text k = new Text();
//定义IntWritable值为1
IntWritable v = new IntWritable(1);
//重写map方法
//context:林夕上下文,把map阶段的结果传到Reduce阶段中
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//对字符串进行切割之后放到数组中
String[] words = line.split(" ");
//输出
for (String word:words){ //将words数组中的每个单词赋给word
k.set(word);
context.write(k,v);
}
// context.write(key, value);
}
}Reduce阶段的处理过程
在Map阶段输出与Reduce阶段输入之间有一个Shuffle过程。Shuffle过程也被称为数据魂系过程,作用是将键相同的键值对进行汇集,并将键相同的值存入同一列表。
评论区